
Despite the many partnerships and relationships now between fintech and the banking giants the Davids are coming for the Goliaths.
Whether a large international Bank, Regional, Community, or Credit Union the emergence of FinTech non-bank startups is changing the competitive landscape in financial services, forcing traditional institutions to rethink the way they do business.
Adopting a data science approach is critical to the future of organizations. Nowhere is this more evident than in the banking industry where business model disruption is rife.
Anwendungsfall
Banks use analytics to determine which financial products or services to offer to which customers.
With many products, each one sitting on separate systems, not necessarily talking to each other means it is extremely difficult to optimize at the customer level.
A customer may be offered a product, but may not meet the bank’s risk requirements or it may be priced inappropriately for the customer risk profile.
With the right tools and expertise, banks can quickly solve immediate data activation challenges to develop a single unified view of the customer.
However often lack of useable enterprise-wide data and analytical capabilities present a broader enterprise challenge that prevents scaling benefits both volume and quality across other interrelated business activities. To integrate data-enabled decision-making across the entire organization a comprehensive data strategy is necessary that includes the means to overcome various other challenges.
Herausforderung
Gain value from data science while conforming to supervisory regulations.
In order to operate data science in a financial institution in a compliant manner, the regulations of the supervisory authorities must be fulfilled. These include, in particular, transparency, reproducibility, and role separation.
Lösung
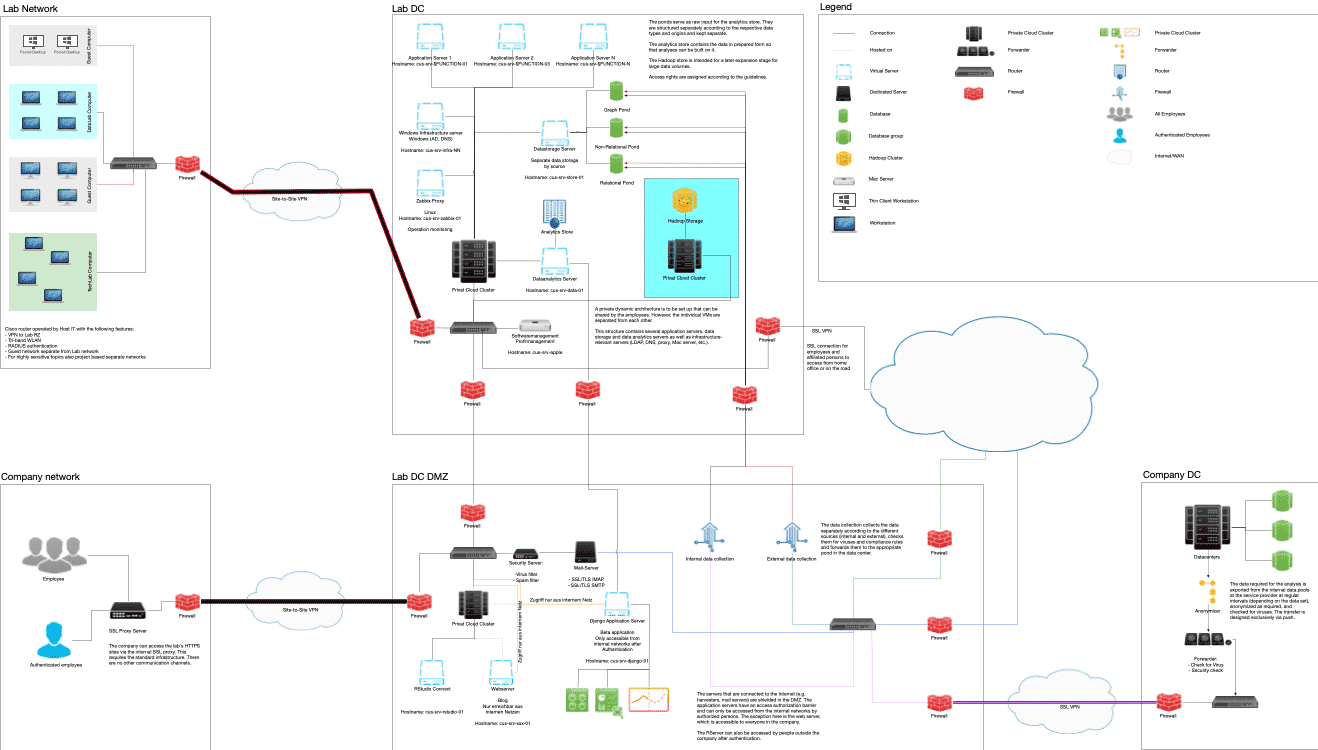
A data science platform was designed that orchestrates various technologies incorporating the regulatory requirements to ensure compliance with the rules set by the supervisory authorities while maintaining the greatest possible freedom for analysts and developers.
Ergebnis
The Data Science Platform was implemented as a test environment and fully automated. An audit tested the environment and found it compliant with regulatory requirements.
The Bank is positioned to drive innovation and tackle domain challenges. Able to apply data science across all activities including customer acquisition, retention, credit risk management.
These and other banking domain challenges can be resolved by the very technology that’s caused the disruption, but the transition from legacy systems to innovative solutions hasn’t always been easy.
A data science platform provides the foundation and roadmap for any organization to compete in the digital economy.
Technologien
A Hadoop cluster stack (Kafka, Hive, Spark, Storm, MapReduce, Mahout, TensorFlow, and various technologies ) was built out with 4 additional employees to enable the processing of large amounts of data and integrate this architecture into the data science platform.
Data Science-Anwendung
RStudio Packet Manager, with Enterprise Firewall upstream, is responsible for versioning and orchestrating the packages used in R and Python and serves as an internal package manager. The RStudio IDE provides the development environment for Data Science projects and supports automatic testing (in GitLab) and (semi-)automatic documentation with packages like Roxygen and TestThat. GitLab enables versioning and the automatic testing of developed scripts. RStudio Connect Server (in collaboration with Tableau Server ) enables the presentation of dashboards, reports, functions, etc. for technologically unsophisticated users.
Bereit für die Zusammenarbeit?
Solve complex problems with data science and AI. Make decisions based on evidence, not instincts, and develop a sustainable edge.
Once a company determines data science should be integral to the business they are faced with various considerations, questions, constraints, and choices;
Do they go with ‚off the shelf domain solutions, versus self-reliance or a combination? Open-source versus proprietary, codeless/low code and code. The impact of these choices is far-fetching.
The option of buying off-the-shelf technologies from AI vendors can work for smaller firms or where applications require minor customization. But as business complexities increase, the application of AI becomes progressively targeted and strategically important. Companies that rely solely on plug-and-play AI solutions jeopardize long-term value creation.
Companies benefit tremendously from the ability to develop data models from the ground up creating their own AI intellectual property and the advantages of independently scaling volume and quality.
The advantages of a self-reliance data science and code-first approach are resounding;
- Flexible: No black-box constraints. Access and combine all your data, analyze and present it exactly as you need to.
- Iterative: Quickly make changes and updates in response to feedback, and then share updates with your stakeholders.
- Reusable and extensible: Tackle similar problems in the future and extend to novel problems as circumstances change.
- IP Rights: A growing and valuable source of IP
- Inspectable: Combined with version control – Track changes over time, discover errors, and audit the approach.
- Reproducible: Combine with the environment and package management, ensure that you can rerun and verify analyzes.
Take a look at how a data solution (the bank owns) helped them improve small business lending